
 Yahoo Finance
Yahoo Finance 'Visual' AI models might not see anything at all
The latest round of language models, like GPT-4o and Gemini 1.5 Pro, are touted as "multimodal," able to understand images and audio as well as text. But a new study makes clear that they don't really see the way you might expect. In fact, they may not see at all.
To be clear at the outset, no one has made claims like "This AI can see like people do!" (Well, perhaps some have.) But the marketing and benchmarks used to promote these models use phrases like "vision capabilities," "visual understanding," and so on. They talk about how the model sees and analyzes images and video, so it can do anything from homework problems to watching the game for you.
So although these companies' claims are artfully couched, it's clear that they want to express that the model sees in some sense of the word. And it does — but kind of the same way it does math or writes stories: matching patterns in the input data to patterns in its training data. This leads to the models failing in the same way they do on certain other tasks that seem trivial, like picking a random number.
A study — informal in some ways, but systematic — of current AI models' visual understanding was undertaken by researchers at Auburn University and the University of Alberta. They tested the biggest multimodal models on a series of very simple visual tasks, like asking whether two shapes overlap, or how many pentagons are in a picture, or which letter in a word is circled. (A summary micropage can be perused here.)
They're the kind of thing that even a first-grader would get right, yet they gave the AI models great difficulty.
"Our seven tasks are extremely simple, where humans would perform at 100% accuracy. We expect AIs to do the same, but they are currently NOT," wrote co-author Anh Nguyen in an email to TechCrunch. "Our message is, 'Look, these best models are STILL failing.'"

The overlapping shapes test is one of the simplest conceivable visual reasoning tasks. Presented with two circles either slightly overlapping, just touching or with some distance between them, the models couldn't consistently get it right. Sure, GPT-4o got it right more than 95% of the time when they were far apart, but at zero or small distances, it got it right only 18% of the time. Gemini Pro 1.5 does the best, but still only gets 7/10 at close distances.
(The illustrations do not show the exact performance of the models but are meant to show the inconsistency of the models across the conditions. The statistics for each model are in the paper.)
Or how about counting the number of interlocking circles in an image? I bet an above-average horse could do this.
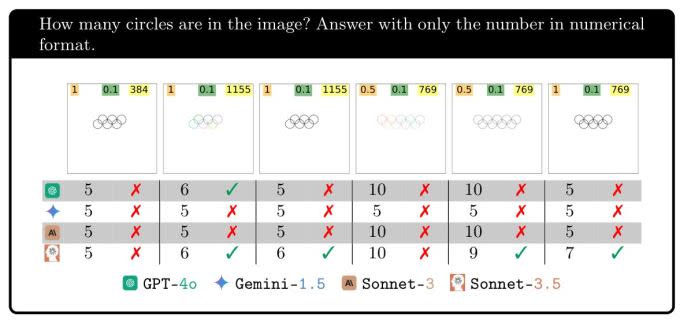
They all get it right 100% of the time when there are five rings, but then adding one ring completely devastates the results. Gemini is lost, unable to get it right a single time. Sonnet-3.5 answers six … a third of the time, and GPT-4o a little under half the time. Adding another ring makes it even harder, but adding another makes it easier for some.
The point of this experiment is simply to show that, whatever these models are doing, it doesn't really correspond with what we think of as seeing. After all, even if they saw poorly, we wouldn't expect six-, seven-, eight- and nine-ring images to vary so widely in success.
The other tasks tested showed similar patterns; it wasn't that they were seeing or reasoning well or poorly, but there seemed to be some other reason why they were capable of counting in one case but not in another.
One potential answer, of course, is staring us right in the face: Why should they be so good at getting a five-circle image correct, but fail so miserably on the rest, or when it's five pentagons? (To be fair, Sonnet-3.5 did pretty good on that.) Because they all have a five-circle image prominently featured in their training data: the Olympic Rings.

This logo is not just repeated over and over in the training data but likely described in detail in alt text, usage guidelines and articles about it. But where in their training data would you find six interlocking rings. Or seven? If their responses are any indication: nowhere! They have no idea what they're "looking" at, and no actual visual understanding of what rings, overlaps or any of these concepts are.
I asked what the researchers think of this "blindness" they accuse the models of having. Like other terms we use, it has an anthropomorphic quality that is not quite accurate but hard to do without.
"I agree, 'blind' has many definitions even for humans and there is not yet a word for this type of blindness/insensitivity of AIs to the images we are showing," wrote Nguyen. "Currently, there is no technology to visualize exactly what a model is seeing. And their behavior is a complex function of the input text prompt, input image and many billions of weights."
He speculated that the models aren't exactly blind but that the visual information they extract from an image is approximate and abstract, something like "there's a circle on the left side." But the models have no means of making visual judgments, making their responses like those of someone who is informed about an image but can't actually see it.
As a last example, Nguyen sent this, which supports the above hypothesis:

When a blue circle and a green circle overlap (as the question prompts the model to take as fact), there is often a resulting cyan-shaded area, as in a Venn diagram. If someone asked you this question, you or any smart person might well give the same answer, because it's totally plausible … if your eyes are closed! But no one with their eyes open would respond that way.
Does this all mean that these "visual" AI models are useless? Far from it. Not being able to do elementary reasoning about certain images speaks to their fundamental capabilities, but not their specific ones. Each of these models is likely going to be highly accurate on things like human actions and expressions, photos of everyday objects and situations, and the like. And indeed that is what they are intended to interpret.
If we relied on the AI companies' marketing to tell us everything these models can do, we'd think they had 20/20 vision. Research like this is needed to show that, no matter how accurate the model may be in saying whether a person is sitting or walking or running, they do it without "seeing" in the sense (if you will) we tend to mean.
